
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 인공지능
- CNN
- SVM
- SGD
- 컴퓨터 비전
- 머신러닝
- cs231n
- Unsupervised learning
- 비용함수
- Regularization
- pre-trained
- 백준
- 파이썬
- Computer Vision
- CPP
- OpenGL
- 컴퓨터 그래픽스
- logistic regression
- C++
- 그래픽스
- 딥러닝
- recommender system
- Kaggle
- 로지스틱 회귀
- petal to metal
- 추천 시스템
- Vision
- neural network
- Support Vector Machine
- 신경망
- Today
- Total
kwan's note
Stochastic gradient descent(SGD) -확률적 경사 하강법 본문
Stochastic gradient descent(SGD) -확률적 경사 하강법
kwan's note 2021. 2. 7. 23:42출처: machine learning by andrew ng, stanford cousera lecture
수강일시: 2021.02.06
reminder-by-kwan.tistory.com/89?category=962582
gradient descent(경사하강법)
출처: machine learning by andrew ng, stanford cousera lecture 수강일시: 2021.01.24 reminder-by-kwan.tistory.com/88 Cost function -비용함수/ 손실함수 출처: machine learning by andrew ng, stanford cou..
reminder-by-kwan.tistory.com
이번시간에는 데이터세트가 매우 큰 경우를 생각해 보고자 한다.
일반적으로 데이터의 양이 적을때는 데이터가 많을수록 좋은 경향을 보였다.
때로는 어떤 학습모델을 선택하느냐보다 데이터의 수가 더 좋은결과를 나타내기도 했다.

왼쪽의 경우 데이터가 더 많아진다면 더 나은 성능을 보일것으로 생각되지만 오른쪽의 경우는 데이터를 더 모으는것보다 feature를 더 추출하는것이 나아 보인다.
하지만 데이터가 매우많은경우 이를 학습하는데 너무 많은 시간이 필요하기도 하다.
이전에 다뤘던 gradient descent 방법을 다시한번 생각해보자.
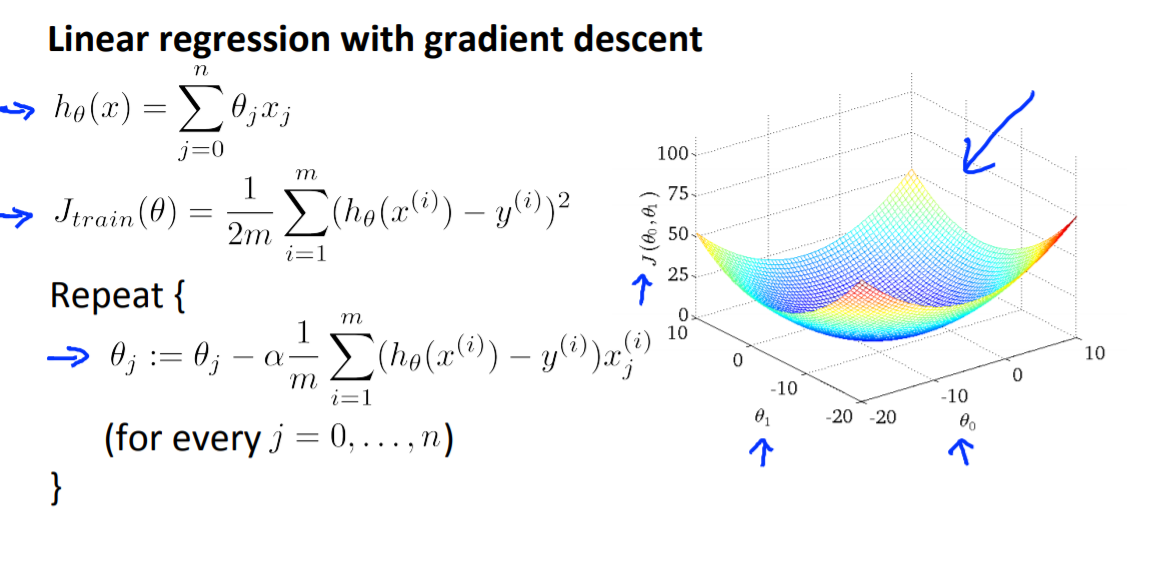
이는 매우 정교한 학습방법이지만 모든 특성 j에 대해서 i=1부터 i=m까지 모든 사람에 대한 미분을 진행해서 계산해야하므로 computaionaly expensive하다.
따라서 다음 방법을 고안했다.

SGD 방법은 모든 feature에 대해 한개의 데이터만 이용해 기울기를 정하고 그만큼 움직이는 것이다.
이는 얼핏생각하면 매우 부정확해보이고 원하는 방향이 아닌 다른 방향으로 갈 확률이 높아보이지만 먼저 data를 랜덤하게 섞은다음 매우높은 반복을 진행한다면 길을 꼬불꼬불 하더라도 결국 원하는 결과를 얻을 수 있게 된다.

즉 m이 매우 큰 경우 이는 굉장히 효과적이다.
n도 매우 큰경우 한번만 해도 되지만 크기에 따라 10회정도까지는 반복해 줄 수 있다. 그럼에도 GD보다 훨씬 적은 시간을 필요로 한다. (ex m=1,000,000 n=100,000 일때 GD는 100,000,000,000회의 연산이 필요하지만
5번 repeat 하는 SGD의 경우 500,000의 연산만 반복하면 된다.
다음으로는 이를 일부 개선한 mini batch 방법을 살펴보도록 하겠습니다.
강의자에 따라 mini batch도 SGD의 일부로 강의하기도 하지만 andrew ng의 학습순서에 따라 진행하였습니다.
reminder-by-kwan.tistory.com/110
'ML and AI > Machine learning - Andrew Ng' 카테고리의 다른 글
| online learning , map reducing -온라인 학습, 병렬 학습 (0) | 2021.02.08 |
|---|---|
| Mini batch gradient descent (0) | 2021.02.07 |
| Collaborative filtering - 협업 필터링 (0) | 2021.02.07 |
| recommendation system - 추천 시스템 (content based) (0) | 2021.02.07 |
| Anomaly Detection - 이상값 탐지 (0) | 2021.02.07 |



