
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 비용함수
- recommender system
- petal to metal
- logistic regression
- Unsupervised learning
- 그래픽스
- 컴퓨터 그래픽스
- 로지스틱 회귀
- 추천 시스템
- CNN
- 백준
- Regularization
- 머신러닝
- Kaggle
- SGD
- C++
- OpenGL
- pre-trained
- SVM
- 컴퓨터 비전
- 딥러닝
- neural network
- cs231n
- CPP
- 인공지능
- Vision
- 파이썬
- Support Vector Machine
- Computer Vision
- 신경망
- Today
- Total
kwan's note
Backpropagation -역전파 본문
출처: cs231n
이전 lecture
reminder-by-kwan.tistory.com/116
linear classification with softmax - 소프트맥스 회귀
출처 : cs231n lecture3 www.youtube.com/watch?v=h7iBpEHGVNc 이번에는 저번시간에 이어서 linear classification의 방식에 대해 알아보도록 하겠습니다. reminder-by-kwan.tistory.com/115 linear classificatio..
reminder-by-kwan.tistory.com
지금까지 loss function을 구하고 gradient descent 방식을 통해 optimize를 진행했습니다.
이제는 neural network에서 중요한 개념중 하나인 역전파에 대해 알아보겠습니다.
coursera machinel learning course에서 역전파에 대해 학습한 내용
(reminder-by-kwan.tistory.com/98?category=962582)과 동일한 내용이지만 이번에는 내용 요약보다는 설명을 위주로 작성하겠습니다.
먼저 간단한 예시를 들어보겠습니다.

위와같이 f= (x+y)z 일때 각 연산을 노드로 표현하였습니다.
우리는 df/dx df/dy df/dz 즉 각 input이 결과에 얼마나 영향을 주는지를 계산하고 싶습니다.
초록색은 각 노드의 계산값이 나오게 됩니다.
이렇게 앞으로 계산해 나가는것을 정방향 전파라고 합니다. 이제 실제로 구하고 싶은 값들을 구해보고자 합니다.
먼저 x+y를 q라고 하면 f=qz가 됩니다. q=x+y에서 x와 y에 대해 편미분을 하면 1이나옵니다.


결과값 f=-12에서 이를 f로 편미분하면 당연히 1이됩니다. 이를 함수값아래 빨간색으로 적었습니다.
다음으로 df/dz를 구해봅시다 12/(-4)로 3을 얻습니다.
동일한 방식으로 df/dq를 계산하면 -4입니다. 이제 df/dy를 구해봅시다.
df/dy는 연쇄법칙(chain rule)을 이용해 계산하면 됩니다.


이렇게 모든 input value에 대해 f를 편미분 한 값을 얻었습니다.
이처럼 역전파 방법은 먼저 input을 받고 정방향 계산을 하고 해당 함수에 대해 local gradient를 계산합니다. 정방향 전파가 끝나면 마지막 값으로 부터 gradient를 계산해 나가면서 local gradient 를 이용해 역방향으로 gradient 를 계산해 나갑니다.


이런 방식을 통해 전체 함수에 대한 input value의 편미분값을 얻을 수 있습니다.
또다른 예시를 살펴 보도록 하겠습니다. 앞에서 한단계씩 차근히 풀어봤으니 자세한 설명보다는 결과를 위주로 보겠습니다.

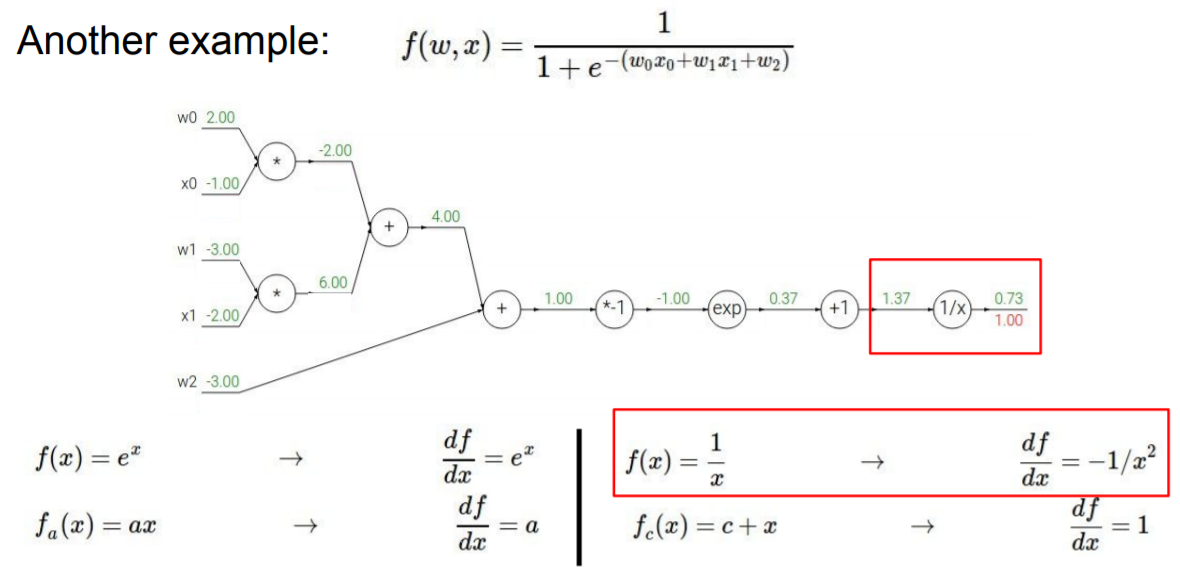



위와 동일한 방식으로 역전파를 진행해 input value가 어떤 영향을 미치는지 확인해 보았습니다.
우리는 모든 계산을 하나씩 node를 분해해서 계산했지만 사실 중간에는 sigmoid 함수가 있었습니다.
모든 계산을 node로 분해할 필요 없이 sigmoid function을 단일 노드로 사용해도 괜찮습니다.

이제는 input 이 상수가 아닌 벡터일때를 살펴보도록 하겠습니다.
우리가 vision이나 nlp등 전통적인 machine learning이 아닌 딥러닝에서 다룰 대부분의 내용 또한 이러한 벡터화된 값들일 것 입니다.
그렇다면 이제 우리가 계산했던 편미분값은 자코비안 행렬이 될 것입니다.


64x64의 아주작은 흑백 이미지도 minibatch 학습을 하면 409600x409600의 행렬이되고 이는 엄청난 연산이 필요해 진다. 실제 이미지는 이것보다 훨씬 크게 되고 이 전체를 계산하기에 매우 불리하다.
따라서 역전파를 통해 각 input value가 어떤 기울기를 갖는지 계산하고자 한다.
이제 이 벡터에서의 역전파 알고리즘을 다시 살펴보자.
W dot x 의 L2 norm을 계산하는 network가 있을때이다.


먼저 이전과 같이 정방향으로 연산을 완료하고 L2(결과)로부터 역전파를 진행해 나간다.
df/dq는 2q이므로 해당 q값(W dot x)의 두배를 연산의 local gradient로 저장한다. 그리고 또 다시 역전파를 진행해 나가면 df/dw로 다음과 같은 결과를 얻을 수 있다.
여기서 유의할 점은 항상 local gradient와 해당 value값의 차원이 동일해야 한다는 것이다.


이로써 neural network의 주요 개념인 역전파에 대해 알아보았습니다.
'computer vision > cs231n-Stanford' 카테고리의 다른 글
| linear classification with softmax - 소프트맥스 회귀 (0) | 2021.02.14 |
|---|---|
| linear classification, SVM - 선형 분류 (0) | 2021.02.14 |
| k nearest neighbor - k 최근접 이웃 (0) | 2021.02.14 |
| cs231n (0) | 2021.02.13 |


