
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 파이썬
- 추천 시스템
- recommender system
- 로지스틱 회귀
- 컴퓨터 비전
- 인공지능
- SGD
- 신경망
- Regularization
- 그래픽스
- 딥러닝
- logistic regression
- Computer Vision
- 컴퓨터 그래픽스
- Support Vector Machine
- 머신러닝
- CNN
- petal to metal
- Kaggle
- CPP
- pre-trained
- C++
- neural network
- Vision
- 비용함수
- SVM
- OpenGL
- 백준
- cs231n
- Unsupervised learning
- Today
- Total
kwan's note
Pandas(판다스) 기본연산 활용하기 본문
출처: 부스트코스-머신러닝을 위한 파이썬
수강일시:2021.01.16
이번 강의는 구조화된 데이터의 처리를 지원하는 Python 라이브러리인 Pandas의 여러 기능과 사용하는 방법 등을
설명하는 강의입니다.
pandas는 구조화된 데이터의 처리를 지원하는 python라이브러리로 엑셀등과 같은 데이터시트를 처리하는 다양한 함수를 내장하고 있어서 데이터를 처리할때 유용하게 사용할 수 있다.
이를 정리하면
- 구조화된 데이터의 처리를 지원하는 Python 라이브러리
- 고성능 Array 계산 라이브러리인 Numpy와 통합하여, 강력한 “스프레드시트” 처리 기능을 제공
- 인덱싱, 연산용 함수, 전처리 함수 등을 제공
의 역할을 한다고 볼 수 있다.

한개의 column을 series라고 하고 이러한 series의 모임을 dataframe이라고 한다.
시리즈를 처리하는 방법들
dataframe을 처리하는 방법들
이러한 처리, 삭제등은 일반적으로 원본데이터를 바꾸지 않고
copy된 데이터를 이용하여 처리한다.
이는 원본데이터가 훼손되는것을 막기 위해서이고 만약 원본데이터를 변경하고 싶으면
inplace = True를 통해 변경을 허용해준다.
index 변경
data drop
dataframe에서 연산은 해당 index를 기준으로 동일한 index를 가진 값들끼리 연산한다.
아래 예시를 보면 index가 a b c d...일때 동일한 인덱스를 가진 값들끼리 더해주게 된다,
series에서도 map함수를 사용해서 매핑할 수 있다.
기존 map과 동일하게 function(+ lambda) ,dict ,sequence형 자료도 가능하다.
map이 아닌 apply를 사용하면 전체 column에 함수를 적용시킨다.

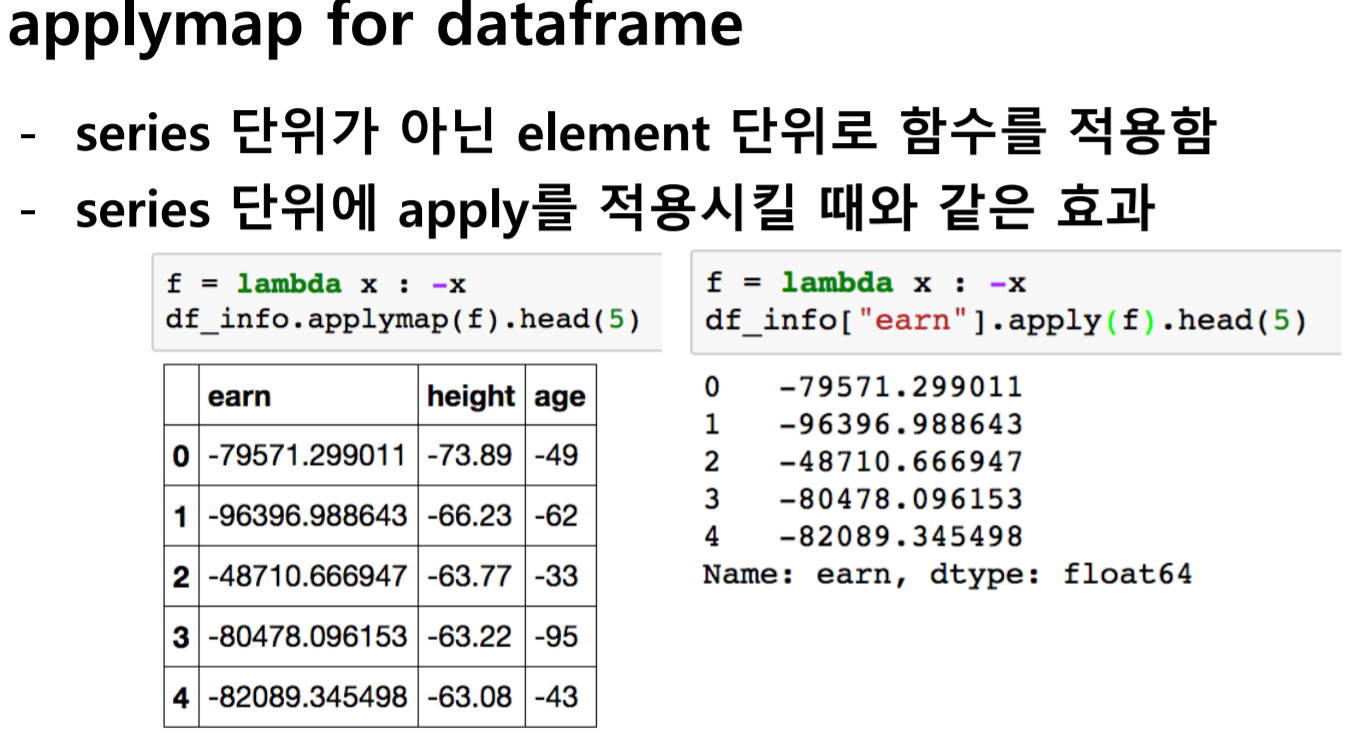
다음으로 built in function들의 일부를 살펴보자.
describe함수는 데이터의 요약정보를 알려준다.
count ,mean, std ,min, 1분위값, 2분위값, 3분위값등의 통계데이터를 제공한다.
unique 함수는 유일한 값들을 반환해준다.
이외에도 비슷하게 사용할 수 있는 sum is_null 등이 있고
sort_value를 통해 column값을 기준으로 데이터를 sorting 할 수 있도록 한다.
corr을 이용해서 correlation 즉 상관계수를 구할 수 있고
cov를 이용해서 covariance즉 공분산을 구할 수 있다.
'ML and AI > Python for ML' 카테고리의 다른 글
| Data Handling - Assignment(Numpy Lab) (0) | 2021.01.17 |
|---|---|
| 데이터 전처리 Data Handling - Data cleansing (0) | 2021.01.16 |
| Numpy(넘파이) 기본연산 활용하기 (0) | 2021.01.10 |
| Machine Learning Overview-머신러닝 기본 용어 (0) | 2021.01.10 |
| Assignment - Basic Linear Algebra -list만 사용하여 행렬 연산하기 (0) | 2021.01.10 |


