
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- recommender system
- CPP
- 컴퓨터 그래픽스
- CNN
- petal to metal
- 머신러닝
- Vision
- 신경망
- Support Vector Machine
- Regularization
- 인공지능
- SVM
- Kaggle
- 딥러닝
- Computer Vision
- 컴퓨터 비전
- SGD
- pre-trained
- OpenGL
- 추천 시스템
- neural network
- cs231n
- 비용함수
- C++
- 그래픽스
- logistic regression
- Unsupervised learning
- 로지스틱 회귀
- 백준
- 파이썬
- Today
- Total
kwan's note
데이터 전처리 Data Handling - Data cleansing 본문
출처: 부스트코스-머신러닝을 위한 파이썬
수강일시:2021.01.16
www.boostcourse.org/ai222/lecture/24076/
머신러닝을 위한 파이썬
부스트코스 무료 강의
www.boostcourse.org
학습 목표
데이터에 있는 여러 이슈(ex. 결측치, scale 문제 등)와 이 이슈들을 처리하기 위해 사용하는 방법들을 소개하고, pandas
를 이용하여 데이터를 cleansing 하는 방법에 대해 공부합니다.
데이터를 이용해 어떠한 output을 얻는 과정에서 결측치에 대한처리나 sacling등의 전처리는 매우 중요한 요소이다.
데이터 전처리는 데이터를 활용하기 전에 결측치, 필요없는값, 오류등을 파악하여 제거하거나 변형하면서도 원본 데이터의 경향을 훼손시키지 않는 일을 말한다.
이러한 전처리가 제대로 이루어 지지 않는다면 유용한 데이터를 가지고도 쓸모있는 결과값을 얻지 못 할 수도 있고 잘못된 전처리로 인해 전혀다른 결과를 얻을수도 있다.
전처리의 기술적인 내용, 사용 방법 먼저 살펴보도록 하겠다.
이러한 데이터처리는 데이터의 질을 높이는 수단이다.

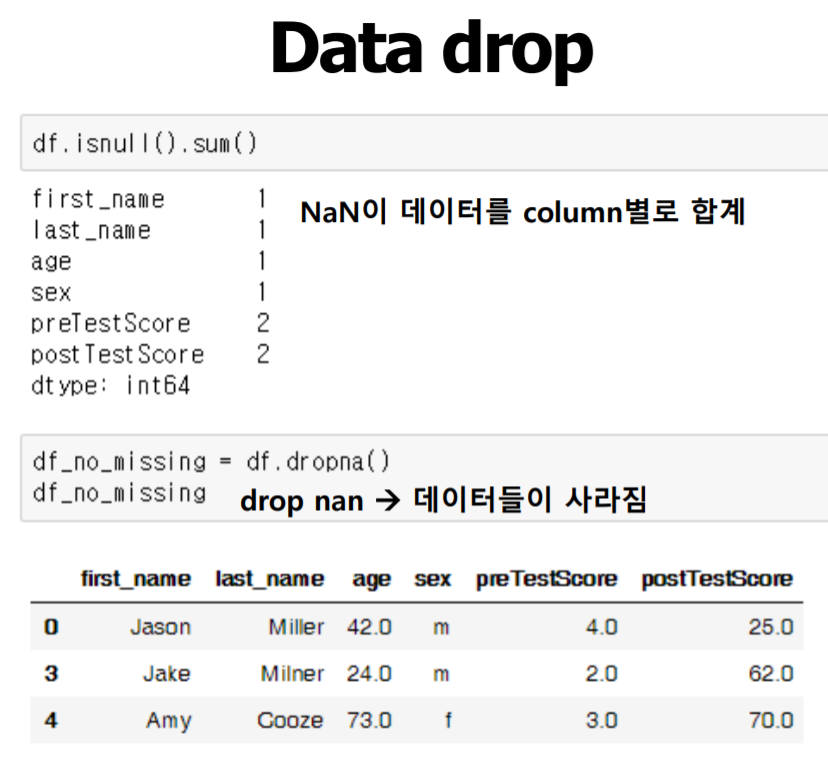
가장 먼저 데이터가 없는경우 (NULL DATA)의 처리에 대해 알아보겠다
데이터가 없는경우 취할수 있는것은
1. 데이터가 없는 모든 row를 drop
2. 데이터가 없는 최소개수를 정해서 sample을 drop
3. 데이터가 많이 빈 경우 feature 자체를 drop
4. 최빈값, 평균값, 중앙값등으로 비어있는데이터를 채우기
데이터 drop

data fill


다음으로 이산형 데이터의 처리에 관해 살펴보도록 하자.
이산형 데이터의 경우 데이터셋의 크기만큼 binary feature를 생성해서 처리한다.
-> one hot encoding


데이터의 크기가 큰 경우 구간을 나눠서 구간에 해당하는 값을 처리한다.
->data binding

scikit-learn(싸이킷런) 의 preprocessing 패키지도 라벨 원핫등 지원함.
마지막으로 데이터값의 범위가 커서 어떠한 데이터가 다른데이터에 비해 영향을 많이 미치게 될 때 scaling을 통해 동일한 scale로 맞춰준다.
이를 normalization이라고 한다.


'ML and AI > Python for ML' 카테고리의 다른 글
| Data Handling - Assignment(Numpy Lab) (0) | 2021.01.17 |
|---|---|
| Pandas(판다스) 기본연산 활용하기 (1) | 2021.01.16 |
| Numpy(넘파이) 기본연산 활용하기 (0) | 2021.01.10 |
| Machine Learning Overview-머신러닝 기본 용어 (0) | 2021.01.10 |
| Assignment - Basic Linear Algebra -list만 사용하여 행렬 연산하기 (0) | 2021.01.10 |


