
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- pre-trained
- CNN
- 컴퓨터 비전
- cs231n
- 추천 시스템
- 신경망
- SVM
- 비용함수
- 백준
- 머신러닝
- Kaggle
- 딥러닝
- Regularization
- Computer Vision
- C++
- CPP
- 인공지능
- petal to metal
- 파이썬
- Unsupervised learning
- neural network
- 로지스틱 회귀
- recommender system
- OpenGL
- 그래픽스
- 컴퓨터 그래픽스
- SGD
- logistic regression
- Support Vector Machine
- Vision
- Today
- Total
kwan's note
gradient descent(경사하강법) 본문
출처: machine learning by andrew ng, stanford cousera lecture
수강일시: 2021.01.24
reminder-by-kwan.tistory.com/88
Cost function -비용함수/ 손실함수
출처: machine learning by andrew ng, stanford cousera lecture 수강일시: 2021.01.24 www.coursera.org/learn/machine-learning/home Coursera | Online Courses & Credentials From Top Educators. Join for F..
reminder-by-kwan.tistory.com
to minimize costfunction we would consider gradient descent method.
not only used in linear regression but also used in many other machine learning methods
Imagine that we graph our hypothesis function based on its fields theta_ and theta_ (actually we are graphing the cost function as a function of the parameter estimates). We are not graphing x and y itself, but the parameter range of our hypothesis function and the cost resulting from selecting a particular set of parameters.
We put theta_ on the x axis and theta_ on the y axis, with the cost function on the vertical z axis. The points on our graph will be the result of the cost function using our hypothesis with those specific theta parameters. The graph below depicts such a setup.

The way we do this is by taking the derivative (the tangential line to a function) of our cost function. The slope of the tangent is the derivative at that point and it will give us a direction to move towards. We make steps down the cost function in the direction with the steepest descent. The size of each step is determined by the parameter α, which is called the learning rate.
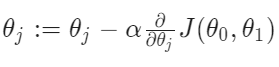
:= means that we assign new value to theta_j
by doing this until convergence, we will ger the local minumim.
we have to be careful of word local minumum because it means not global. if we pick different starting point, we could end up in the different value of theta_j.
we also have to care about simultaneousness of update

we have to carefully design the value of alpha because if it's too small, it takes to much resource to find the optimum. if too large, it might not find the optimum, may be diverge

but we don't have to change the value of alpha as it get near the optimum value because the step get smaller as desecent get smaller.

'ML and AI > Machine learning - Andrew Ng' 카테고리의 다른 글
| logistic regression -로지스틱 회귀 (0) | 2021.01.26 |
|---|---|
| Normal Equation-정규방정식 (0) | 2021.01.26 |
| Cost function -비용함수/ 손실함수 (0) | 2021.01.24 |
| unsupervised learning -비지도학습 (0) | 2021.01.24 |
| supervised learning -지도학습 (0) | 2021.01.24 |



