
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 머신러닝
- SVM
- 로지스틱 회귀
- Unsupervised learning
- cs231n
- petal to metal
- 추천 시스템
- 컴퓨터 비전
- 인공지능
- 파이썬
- Kaggle
- 딥러닝
- Regularization
- C++
- Support Vector Machine
- Vision
- OpenGL
- Computer Vision
- 비용함수
- recommender system
- 컴퓨터 그래픽스
- CNN
- pre-trained
- SGD
- CPP
- 신경망
- neural network
- 그래픽스
- logistic regression
- 백준
- Today
- Total
kwan's note
kernel in SVM- SVM에서 커널 본문
출처: machine learning by andrew ng, stanford cousera lecture
수강일시: 2021.02.04
reminder-by-kwan.tistory.com/102
SVM support vector machine - 서포트 벡터 머신
출처: machine learning by andrew ng, stanford cousera lecture 수강일시: 2021.02.02 reminder-by-kwan.tistory.com/94 regularization - 정규화 출처: machine learning by andrew ng, stanford cousera lectu..
reminder-by-kwan.tistory.com
다음으로는 SVM에서 kernel에 대해 알아보고자 합니다.
그에 앞서 non linear decision boundary 가 있는 문제에 대해 생각해 봅시다.
다음과 같은 문제에 있어 n차다항식을 만드는것은 매우 비효율적이고 복잡해질 것입니다.

따라서 어떤 점들에 대해 이와 가까운 것들을 만드는 커널을 만들고자 하였습니다.
여기서 커널은 cost function에 대해 기존의 theta x를 이용하여 구하는것이 아닌 새로운 함수를 정의해 cost function을 구하는 방식입니다.


가우시안 커널은 가우시안 분포를 이용해 특정 landmark에 가까운 정도를 이용해 커널을 만드는 방식입니다.
즉 landmark와 x의 거리를 계산하여 시그마제곱으로 나눈것에 exp를 취한 값입니다.
따라서 x가 l과 가깝다면1을 멀다면 0을 반환하는 함수입니다.
이를 시각화 하면 다음과 같습니다. 보이는것과 같이 시그마제곱을 조절하여 민감도를 조절할 수 있습니다.
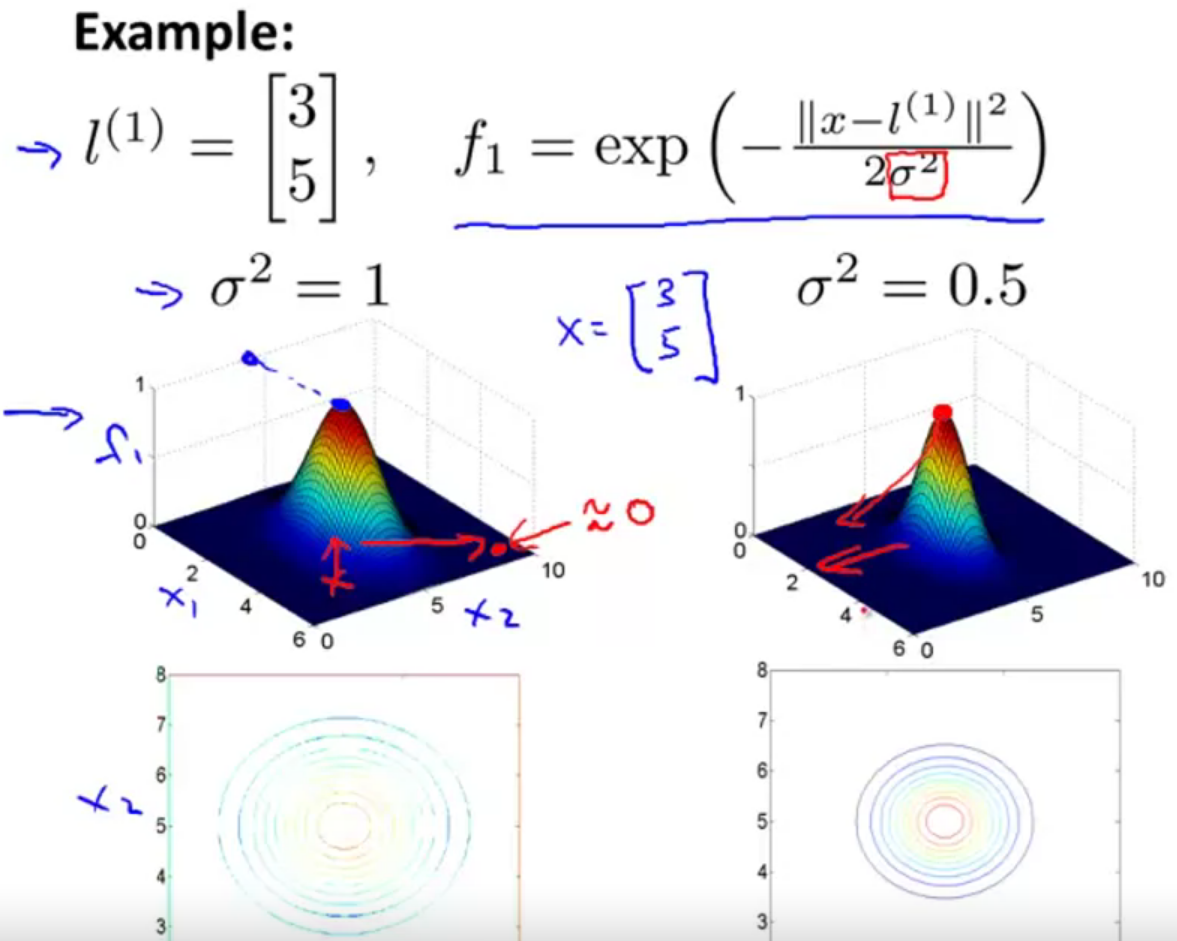

처음에 구하고자 했던 내용을 가우시안 커널을 이용해 구해보자면 대략적으로 위와 같게 됩니다.
이제 이러한 kernel을 만드는 landmark의 위치를 어떻게 특정하고 또 계수들을 어떻게 구하는지 생각해 봅시다.
먼저 모든 training set의 정답에 대해서 landmark로 설정하여 학습을 시키도록 하겠습니다.

모든 training set의 x에대해 이를 l로 두었습니다.
이제 li 는 xi와 동일하게 됩니다. 이렇게 되면 fi의 i번째 값은 항상 1이되고 fi의 non i의 값은 1보다 작을 것입니다. 만약 시그마가 매우 작다면 모두 0이 될 것입니다. 그렇게 된다면 이제 trainset x 대신 f를이용해 표현할 수 있게됩니다.
그러면 다시 SVM training을 kernel f에 대해 진행할 수 있게됩니다.
즉 minimum costfunction을 만족하는 theta값을 찾게 됩니다.

logistic regression에서 람다가 했던 bias variance trade의 역할을
SVM에서는 C가 대신하였습니다.(원리는 동일)
SVM의 kernel에서는 시그마 제곱이 이 역할을 또다시 하게 됩니다.(C와는 별개로)
따라서 이제는 C 혹은 lambda만 결정하는것이 아니라 SVM이 overfitting되었다면 C를 감소시키는것과 시그마제곱을 높이는것 두가지의 선택이 생기는 셈입니다.
가우시안 커널에서 주의할점은 feature scaling이 필요하다는 것입니다. norm(x-L)의 제곱을 하므로 scaling이 되지 않을 경우 특정 feature에 치우치게 될 우려가 발생합니다.
저번시간(reminder-by-kwan.tistory.com/102)에서 배운 SVM의 경우 non kernal SVM이라고 부르기도 합니다.
오늘 배운 가우시안 커널 이외에도 다양한 커널이 존재합니다.

또한 multi calss classification의 경우 one vs all method 를 이용하면 구현할 수 있습니다.
마지막으로 언제 logistic regression을 사용할지, 언제 SVM을 사용할지 생각해보도록 합니다.

다음과 같이 feature의 갯수 (n)과 training set의 갯수(m)의 크기에 따라 다른 접근 이 필요합니다.
하지만 위 수치는 절대적인것은 아닙니다. 따라서 어떤 문제에 어떤 방식을 선택해야하는지 여러 접근을 통해 확인해보는것이 좋습니다. 또 cross validation set을 이용해 정답률이 높은 방식을 사용하는 것도 좋은 방법중 하나가 될 수 있습니다.
'ML and AI > Machine learning - Andrew Ng' 카테고리의 다른 글
| Dimesionality reduction - 차원축소 , PCA( principal component analysis) (0) | 2021.02.06 |
|---|---|
| K means cluster (K 평균 군집) - 군집분석 (0) | 2021.02.05 |
| SVM support vector machine - 서포트 벡터 머신 (0) | 2021.02.04 |
| cross validation and fitting - 교차 검증과 피팅 (0) | 2021.01.31 |
| back propagation in neural network - 역전파 (0) | 2021.01.29 |



