
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- SVM
- Regularization
- 백준
- C++
- 추천 시스템
- 비용함수
- OpenGL
- Computer Vision
- petal to metal
- Unsupervised learning
- neural network
- 파이썬
- CPP
- 신경망
- 컴퓨터 비전
- SGD
- cs231n
- logistic regression
- 컴퓨터 그래픽스
- pre-trained
- Support Vector Machine
- 인공지능
- 딥러닝
- 그래픽스
- Vision
- Kaggle
- 머신러닝
- 로지스틱 회귀
- CNN
- recommender system
- Today
- Total
kwan's note
K means cluster (K 평균 군집) - 군집분석 본문
K means cluster (K 평균 군집) - 군집분석
kwan's note 2021. 2. 5. 02:54출처: machine learning by andrew ng, stanford cousera lecture
수강일시: 2021.02.04
reminder-by-kwan.tistory.com/87?category=962582
unsupervised learning -비지도학습
출처: machine learning by andrew ng, stanford cousera lecture 수강일시: 2021.01.24 supervised learning reminder-by-kwan.tistory.com/86 supervised learning -지도학습 출처: machine learning by andrew..
reminder-by-kwan.tistory.com
이번에는 비지도 학습의 대표적인 방법중 하나인 K means cluster 즉 군집 분석에 대해 알아보도록 하겠습니다.
k means cluster는 자료들을 유사한 성질을 보이는 K개의 군집으로 나타내는 방법입니다.
클러스터링은 다음과 같은곳들에 사용될 수 있습니다.

k means clustering을 그림으로 살펴보도록 하겠습니다.
2 mens clustering의 예제를 이용해서 확인해 보도록 하겠습니다.
먼저 임의의 두점을 찍고 이를 centroid로 정합니다. 다음으로 그 두점에 가까운 점들을 군집으로 포함합니다.


다음으로는 해당 군집의 중심점을 찾아 이를 다시 centroid로 바꾸고 해당 centroid와 더 가까운 점들을 다시 해당 군집으로 만듭니다(군집을 재 정비 합니다)


이제 다시 centroid를 해당 군집의 중심으로 옮기고 해당 centroid를 중심으로 군집을 재 편성하는 과정을 반복합니다.



군집이 더이상 변하지 않고 centroid가 움직이지 않을 때 까지 반복합니다.
이렇게 만들어진 군집의 결과는 위와 같습니다.
이를 pseudo code로 표현하면 다음과 같습니다.

그렇다면 초기 centroid의 initialize는 어떻게 해야하는지 살펴봅시다.
k mean cluster 방법에서 centroid의 intialization은 매우 중요한 부분입니다.
만약 한쪽으로 치우치게 된다면 원하는결과 (이상적인 결과)가 아닌 치우친 결과값이 나오게 됩니다.즉 local optima 에 빠지게 됩니다.
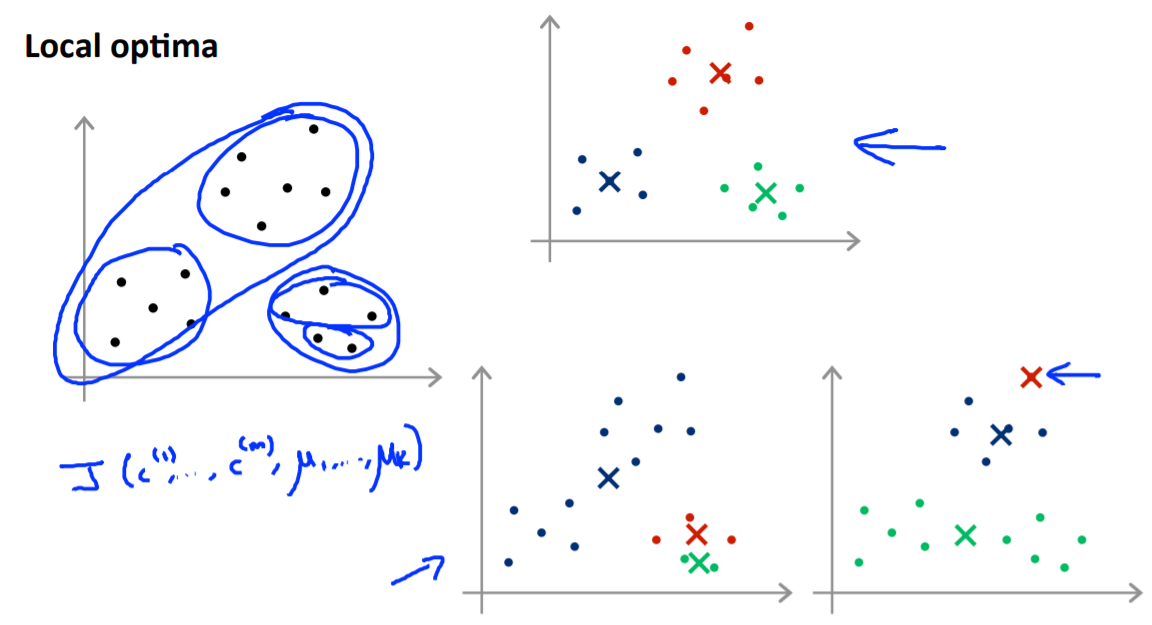
이를 방지하기위해 x위의 점들중 서로 다른 점들로 k개를 골라 intialize하는 것을 수십~수천번까지 반복할 수있습니다.
이는 정해진 숫자는 아니지만 많은게 일반적으로 더 낫지만 너무 많을 필요는 없습니다.
이를 통해 얻어진 값들중 cost function( centroid와 x의 거리합 제곱의 합)이 최소가 되도록 하는 방법을 선택합니다.

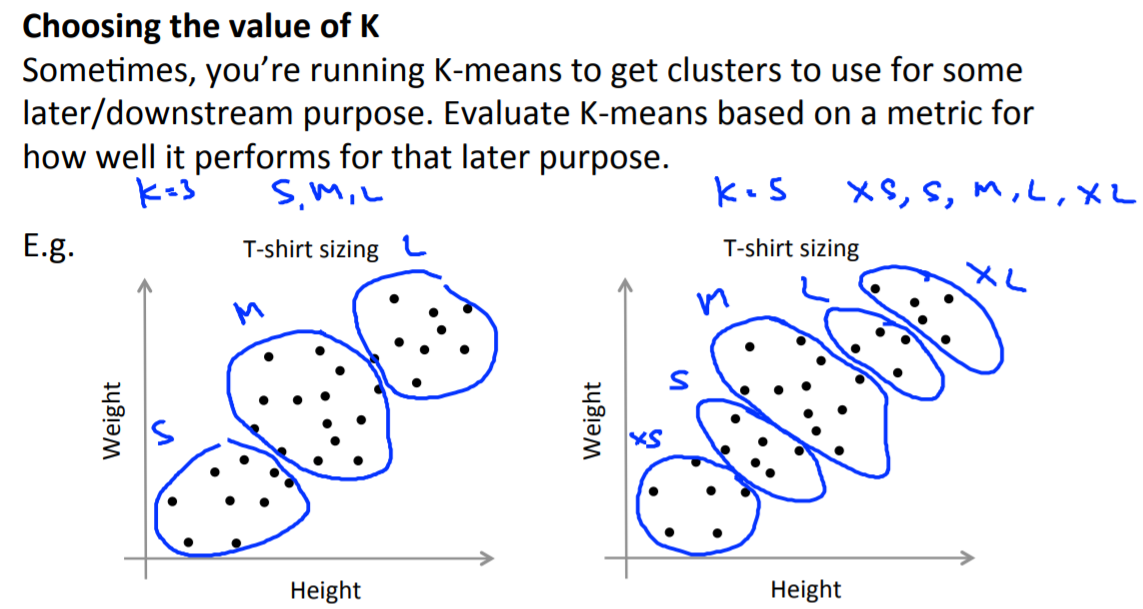
그렇다면 K의 갯수는 어떻게 정할 수 있을까요
먼저 k의 갯수가 많아질수록 cost function의 값이 감소하는것은 명백한 사실입니다.
따라서 descendent method등의 방법은 의미가 없습니다(k=m일때 최소가 되므로).
첫번째 방법은 감소폭이 적어지는 elbow를 찾는 방식입니다.

하지만 이는 elbow가 모호한 경우도 존재하므로 언제나 선호되는 방식은 아닙니다.
다음은 project oriented 방식입니다. 그냥 실제 문제에서 요구되는 cluster의 갯수를 미리 정해놓고 그것을 기준으로 정하는 방식입니다.
이것으로 k means cluster에 대해 학습해보았습니다.
'ML and AI > Machine learning - Andrew Ng' 카테고리의 다른 글
| Anomaly Detection - 이상값 탐지 (0) | 2021.02.07 |
|---|---|
| Dimesionality reduction - 차원축소 , PCA( principal component analysis) (0) | 2021.02.06 |
| kernel in SVM- SVM에서 커널 (0) | 2021.02.04 |
| SVM support vector machine - 서포트 벡터 머신 (0) | 2021.02.04 |
| cross validation and fitting - 교차 검증과 피팅 (0) | 2021.01.31 |



